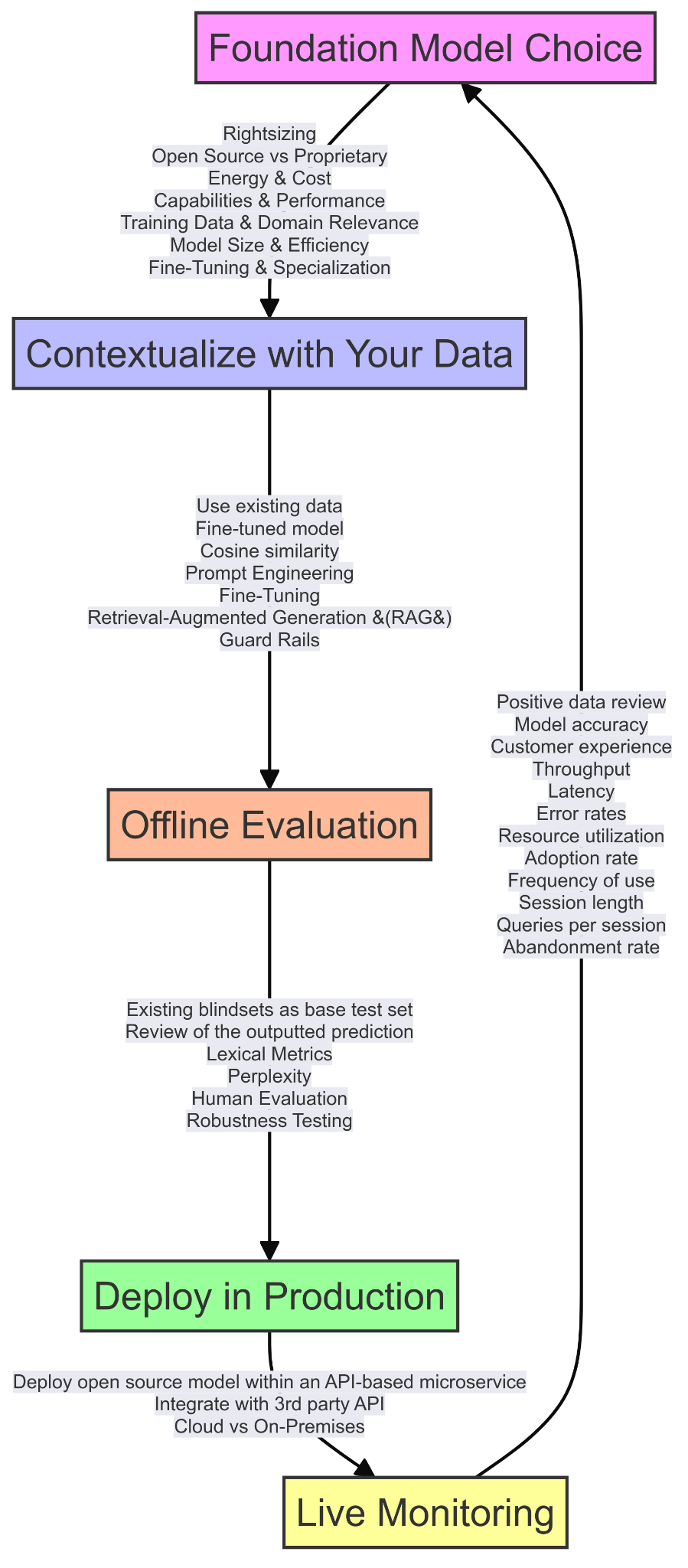
A clearly defined structure and process is essential if you are looking to develop a Generative AI (GenAI) application. Obviously, it's a complex undertaking with many considerations and decisions. To help you get started, here is a brief overview that highlights the five essential steps to incorporate into your process
1. Choose your foundation model
Foundation models are large-scale AI models trained on vast unlabelled datasets and designed to be adapted to various tasks. There are numerous options, including proprietary models, such as GPT-4, Anthropic Claude, Cohere, IBM Granite, as well as open-source models that you can use for free like Llama and GPT-J. Choosing the right model for your specific task or application is a crucial early decision.
You should evaluate models based on factors like their capabilities, performance, cost and alignment with your specific application. You also have to decide whether you can work with a base foundational model or need to find one that's already fine-tuned for the specific task you have in mind.
IBM's 13B Granite model ('granite 13b'), for instance, is a base model with no fine-tuning. However, it is well suited to the enterprise because it has been through a rigorous process to filter out hateful and profane (HAP) content, copyrighted material, GDPR-protected data, and poor-quality data. GPT-4 is fine-tuned to work as a chat model, but it is trained on a large general data set, so it can function as a base model as well.
On open-source communities such as Hugging Face, it's possible to find models that are fine-tuned by the community for specific applications such as summarization or reasoning or for deployment in chat applications. You may be able to find models that are fine-tuned for very specific tasks such as classifying tickets for IT support for example. If you find a fine-tuned model that is specific to your use case, you can avoid the effort and expense of fine-tuning a model yourself.
Some versions of the Granite series models have also undergone fine-tuning, for example, to enhance their ability to follow specific instructions and improve their performance on targeted tasks.*
Other factors to consider include rightsizing, with the number of model parameters a key factor. These are the variables on which the model was trained and can range from millions to billions of parameters. While larger models generally perform better, they require more resources, which impacts infrastructure decisions - and ultimately cost. A bigger model will need more computational power, consume more energy, and increase your costs.
2. Contextualize to your specific use case
Pre-trained foundation models can work well for many general use cases out of the box. However, this approach may not be right for more specialized applications. A pre-trained model may need to undergo a contextualization process to adapt it more closely to the specific use case or task. This is particularly important in industries such as healthcare, finance, legal, and scientific research, where domain-specific terminology, jargon, and semantic relationships are crucial for accurate data interpretation and generation.
One approach to this is prompt engineering, which involves carefully designing input prompts (including providing domain-specific information) to guide the model and improve the quality and focus of the model's outputs so that they are more aligned with the task.
Prompt engineering sits at the intersection of linguistics, psychology, and computer science, necessitating collaboration across disciplines. However, a limitation of prompt engineering is the size of the model's context window - or the amount of information that can fit into a single prompt. If the domain or task requires extensive background information, technical details, or a long sequence of instructions, the model might struggle to process all the necessary information.
Another approach to contextualization is fine-tuning the model with a specialist domain-specific dataset so it is better able to perform the specific target task you have in mind. Typically, fine-tuning is a more complex and technical process than prompt engineering and requires having the required task-specific dataset. Fine-tuning involves training the pre-trained model on a smaller, domain-specific dataset, allowing it to adapt its knowledge and linguistic patterns to the specific characteristics and nuances of that domain.
You can also add specific context relevant to your use case or task with Retrieval Augmented Generation (RAG). This is a way of integrating real-time information, stored in a database or knowledge base, for example, which the AI can access when performing a task. In this way, the AI application can include the most current and relevant domain-specific data in its responses, making its output more accurate and contextually appropriate. RAG can be used in combination with prompt engineering or fine-tuning to further enhance the model's context awareness.
Another consideration at this stage is setting appropriate guard rails. These are tools and strategies to ensure your chosen model's focus is kept within defined boundaries and does not stray into providing inappropriate, problematic, or damaging outputs for example.
3. Offline evaluation
Evaluating your model offline before releasing the AI application to real-world users is obviously a non-negotiable requirement. There have been numerous examples of generative AI applications producing factual errors, bias, and hallucinations that have led to reputational damage or even worse. Many of these issues could have been avoided if the systems had been thoroughly evaluated before going into production.
Offline evaluation usually involves testing a model on a set of predefined tasks and scenarios to assess its performance by comparing the outputs against expected results. This can help identify potential problems, and ensures the model meets the required quality standards before being released to real-world users. It could involve assessing the model's ability to perform tasks such as answering questions related to a set of documents or classifying sentiments.
There are a variety of metrics that are commonly used to evaluate different aspects of a model including its accuracy, precision and relevance. For example, the BLEU (Bilingual Evaluation Understudy) score assesses the AI's ability to produce human-like text for a more natural and engaging user experience. The perplexity score measures the ability of an AI model to understand and predict text, measuring the quality and reliability of the model's outputs.
More complex tasks may require custom evaluation methods and metrics designed to capture specific aspects of performance. You might need to test the model's ability to generate JSON code for an API call for example.
Consider a GenAI model designed to automatically create shopping lists by converting simple text inputs, like 'I need eggs, milk, and bread,' into a structured JSON format that cold be used by a grocery shopping app to categorize items and check availability. You will need to test the model's ability to generate accurate JSON, such as {"groceries": ["eggs", "milk", "bread"]}, ensuring each item is correctly listed under a designated category.
In some cases, it may be possible to use a bigger model, such as GPT-4, to evaluate the outputs of your (smaller) model to reduce manual effort.
Getting human testers involved in assessing aspects of a model's output can be especially valuable for capturing subtle errors or biases. This can involve rating the outputs on various criteria or comparing them side-by-side with human-created examples.
4. Deploy in production
Now you are ready to deploy your generative AI application in production. You need to consider whether it's best to host the application on the cloud or on-premises on your own internal infrastructure.
There are numerous options for running your application in the cloud. All the main cloud providers including IBM Cloud, Microsoft Azure, AWS and Oracle Cloud offer services for deploying and managing GenAI in the cloud. Running your GenAI applications on the cloud as a managed service that automatically scales to your requirements is the most convenient and cost-effective option for many organizations.
If you choose to go the on-premises route, it's highly likely that you have decided this because you have stringent data security, privacy, or regulatory compliance requirements. You want to keep your data and internal code within the confines of your own data center. In certain industries there are specific regulatory demands concerning data storage and processing that might dictate this.
Running your GenAI deployments on-premises is the more complex option and requires significant upfront investment and ongoing maintenance of specialized hardware and software components. You need to ensure your infrastructure has the necessary compute and inference capabilities, storage and networking resources, and software to run an effective deployment - and you need to be able to call on the expertise and skills to manage the application.
5. Constant live monitoring
Once it is in production, it's important to continuously monitor the model's performance and the user experience. Operational monitoring focuses on measuring the efficiency and reliability of the AI model. Key metrics to track include throughput, latency, error rates and resource utilization (CPU, GPU and memory). How many requests is it handling? How long is it taking to process requests?
Tracking usage metrics is crucial for understanding how users interact with the model. To understand and monitor the user experience, you need to focus on tracking aspects of accessibility, and usability. For example, to monitor user experience, focusing on metrics such as frequency of usage, session lengths, queries per session, and abandonment rates can be helpful.
To gain deeper insights into the user experience, consider complementing the usage metrics with qualitative feedback. Techniques like user surveys, interviews, and usability testing can provide valuable context on how users perceive and interact with the AI application.
Remember, the goal of live monitoring is not just to track metrics, but to act on the insights they provide. Use the data to inform ongoing model fine-tuning, user interface enhancements and new feature development.
By constantly iterating based on real-world performance and user feedback, you can ensure your GenAI application remains relevant, reliable, and valuable to users.
* The granite.13b.instruct model has had supervised fine-tuning to enable it to take better instructions to complete enterprise tasks via prompt engineering. the granite.13b.chat model has undergone a novel contrastive fine-tuning after supervised fine-tuning to further improve the model's instruction following, mitigate certain notions of harms, and encourage its outputs to follow certain social norms and have some notion of helpfulness.
This blog was originally published on the IBM Community.