

This is the second in a series of articles in which I describe how Macro 4 transitioned over the years from a traditional mainframe development environment using ISPF and relying on the mainframe natively as a repository to one that today operates a modern hybrid mix of open-source tools along with our own in-house solutions. The changes have helped us increase efficiency, reduce risk and make life easier for the new generation of developers.
In the previous post, I briefly described our development environment from 30 or so years ago and compared it to our modern development stack today. In this article I want to build on that to explain how we started our journey by integrating the Eclipse IDE, which also meant we took on a number of other open-source tools including Apache Maven and Subversion and more.
Anyone who works with developers appreciates that, above all, they love to spend their time coding. They want to be able to book something out of the repository as quickly and easily as possible and build and test it at the click of a button so that they can get back to focusing on coding. This is partly why there's a need to bring in tools to automate the build and test processes.
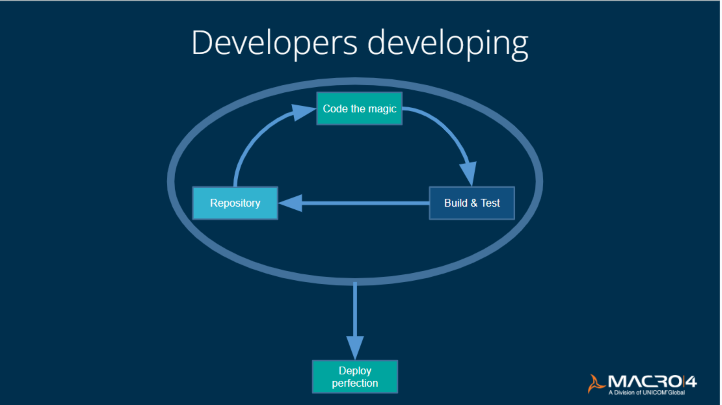
First step: working with Eclipse
Our open-source adoption journey began in the early 2000s. We needed to build Eclipse plugins for our products, as those were the interfaces that people were requesting. We were coding in Java, and it made sense to use the open-source Eclipse IDE. Eclipse helped to streamline the process, allowing developers to access and work on all their source in one place rather than ISPF.
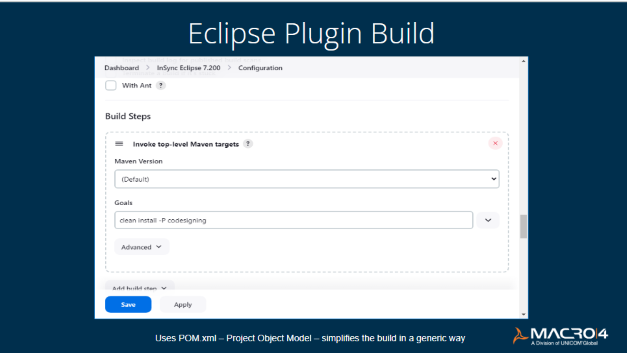
At the same time, Apache Maven gave us a generic way to simplify the build of the Eclipse Plugins. One key benefit was that it helped ensure that we didn't need to rewrite everything each time we introduced a new version of a plugin. By using the POM (Project Object Model) XML file for each version, we were able to minimize the changes we needed to make as we moved from one version to the next.
We were using Subversion as the repository, which integrates with Maven and Jenkins. When we had everything compiled, Jenkins enabled the build. You ask it to Build Now based on what you've created as your inputs and it creates an Artefact file.
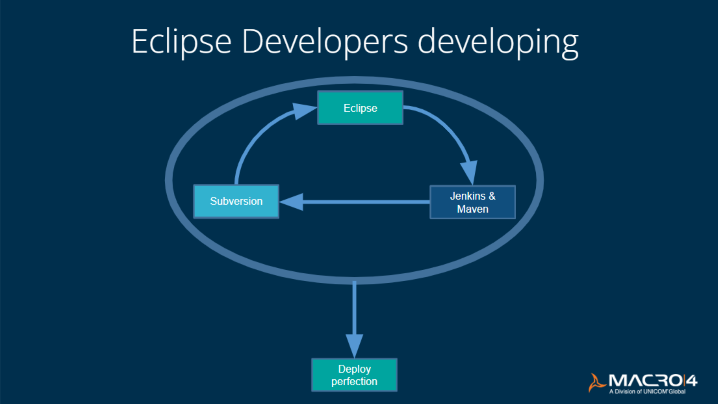
This worked really well so we decided to modernize our Assembler development lifecycle too. We could easily get our source into Subversion, edit the Assembler with Eclipse. Then we would need to use Jenkins and Maven to drive the build.
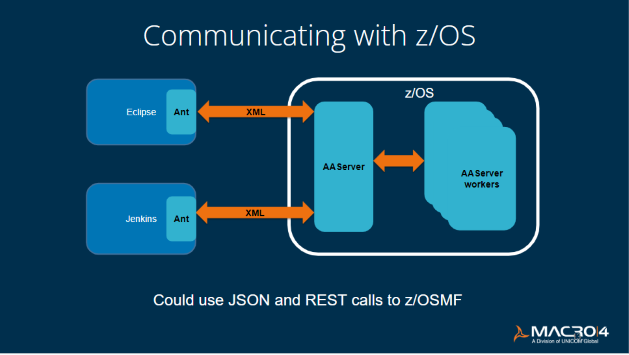
There were difficulties we needed to tackle with the build because Eclipse is running on Windows locally (not on the mainframe). So, with the build and test process, if you are using Jenkins and Maven, you need to work out a way of sending everything over to the z/OS box.
That was a challenge because we had to manage that communication. How do we do all the standard things that you would need to do, like create a data set, create a file, update a file, get a member list, look at the properties of any file - the list goes on. Essentially, we needed to be able to do this on z/OS but prompt it from outside the mainframe via Eclipse - or ask Jenkins to do it.
Thankfully, we already had a piece of technology that we had developed in-house called AAserver, which we could use. AAserver ships as part of common code with some of our products (the likes of DumpMaster, TraceMaster, InSync). With AAserver, we were able to use XML to request what we wanted to do on the mainframe.
The alternative that some other organizations use is to use JSON with rest calls to z/OSMF. However, the concern with this is the risk that you are opening up z/OSMF to developers - which many organizations may be wary of doing because z/OSMF is a very powerful tool.
When doing the Assembly Build, there is more to consider because we wanted to use Ant to automate and locally manage the build. The important thing here is to use standard Ant services because they give you quite a lot of out-of-the-box functionality. Ant relies on a build.xml file for all its instructions, so we needed a build.xml for each type of build that we were going to do - full or partial.
Within that build.xml file, for the full build, there are five steps that need to be taken into account. Four of them are described below (the last one being purge which needs no further explanation).
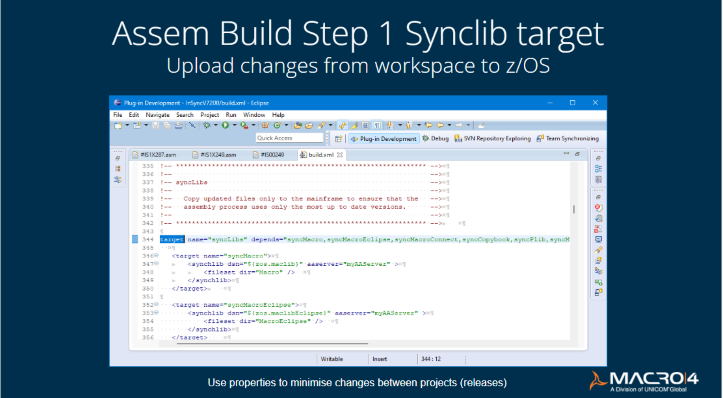
Step 1: Synclib target (upload changs from workspace to z/OS)
This is about updating a project after any development changes have been made, ensuring only changed modules are reassembled and linked.
So, the first thing was that you wanted to only upload to z/OS what had changed. Obviously, when you're working in Eclipse (and the same is true of VS Code), you move everything into your workspace that you might want to change. This could be 15 members of Assembler or 50 pieces of code for JAVA or whatever. But you might actually only make changes to two or three. So there's no point in uploading all 50 - you only want to upload what's changed. The beauty of doing it this way is there's a huge reduction of manual effort and potential errors. This way automatically tracks the changes and uploads the modules only where changes have happened.
Another important step to help minimize the number of changes you need to make every time you have a new version is to define the variables. ANT defines these as properties. Otherwise, you'll create difficulties for the future.
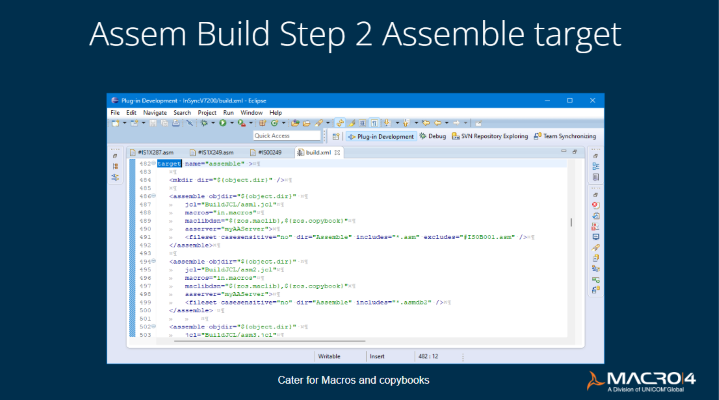
Step 2: Assemble target (synchronize job source, macro and other libraries)
When you upload the code changes from your workspace, you may have made changes to macros and copybooks, which are used by multiple source members. It's essential that every single piece of Assembler code that invokes those macros and copybooks gets automatically reassembled.
This is a major time saver because some organizations have to do this manually. They spend hours laboriously finding and noting down all the occurrences of the macros and copying them to make sure that they are submitted to reassemble everything there.
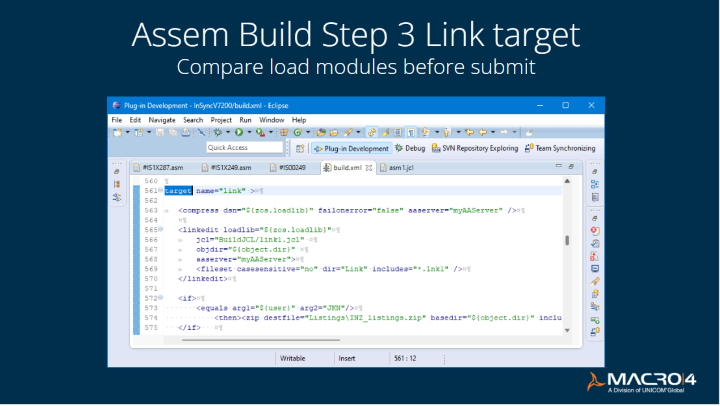
Step 3: Link target Compare load modules before submit Assemble component modules
The next step is to link the different pieces of code and libraries into a single load module once you've assembled them. In some cases, you might have added a whole new part or an entirely new element, so you needed to make sure that you captured and kept those together. Otherwise, you would get very strange results.
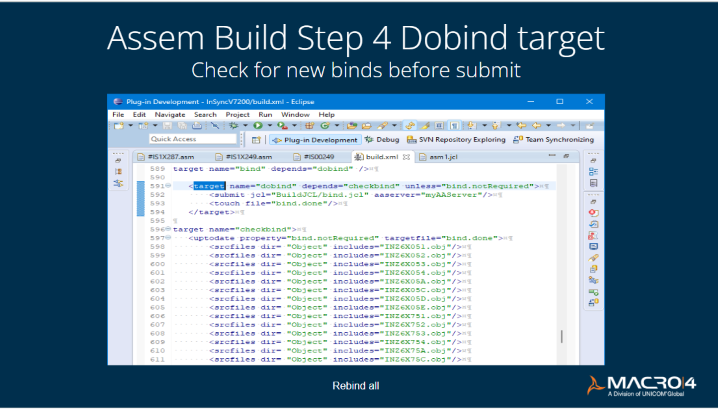
Step 4: Dobind target (check for new binds before submit)
It's important to detect any changes to Db2, if that's involved, which would mean the bind information would change. If there was a change to a Db2 DBRM (Database Request Module), you want to ensure you take the freshest copy of all of them. That would be the cleanest way to make sure that you had everything in there.
Error handling
At all stages, you need to make sure you are effectively handling any errors. We didn't run through the purge at that point because if you get an error through the build process, it's quite useful to have all of the JCL that you've run and all the output from it still left there. You can look at it to get more details, go back, and fix your error. Then you go through the whole thing again. The Purge step only executes if all previous steps completed successfully.
As I mentioned in the introduction, this is the second of three posts which are an account of Macro 4's Open DevOps journey. Look out for the final piece, in which I'm going to explain how we adopted VS Code and how it has helped enhance our development processes.
This blog was originally published on the IBM Community.