

In this series of three blog posts, I want to tell the story of Macro 4's Open DevOps journey, explaining how we have successfully adopted and implemented a variety of open-source tools within the development environment for our mainframe solutions. This includes modern IDEs such as VS Code, version control and collaboration tools such as Git and Subversion as well as others including open-source solutions for build automation, testing and more.
In this initial post, I want to paint a before and after picture to show where we were previously and where we are currently in our journey - as well as to highlight some of the main factors that have triggered the changes we've made.
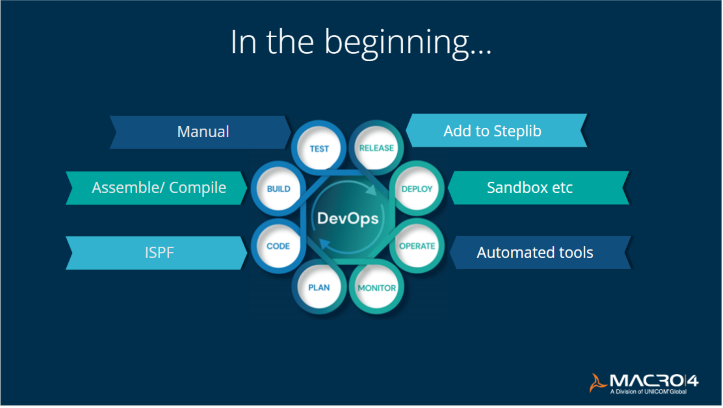
Let's start at the beginning
30 or so years ago most organizations (including us) that were running IBM mainframes would have had their developers editing code directly in ISPF and submitting their assemblies or compilations directly. They were probably testing manually and when they released new code, they would have simply added the module to the STEPLIB in their JCL.
This was in stark contrast to the operations side, where things have been more advanced for many years. The mainframe has always been very heavily managed because there have always been different environments for deployment. Automated tools have existed for around 40 years; there's always been a lot of active monitoring.
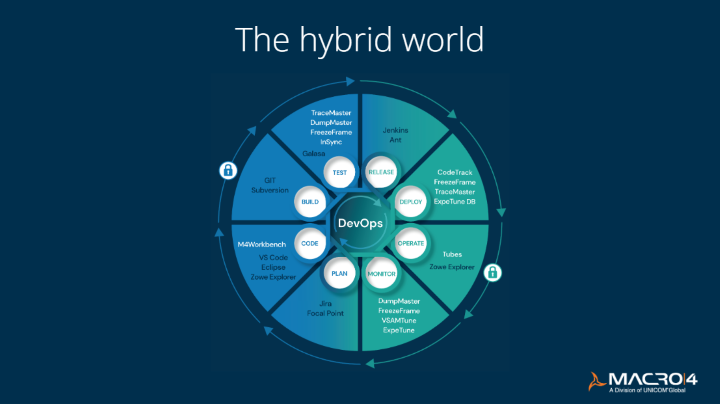
Now: Living in a hybrid world
Fast forward to today and things have changed dramatically with Macro 4 embracing a hybrid world, relying on a mix of tools that we have developed ourselves together with many open-source solutions. The open-source products include VS Code, Eclipse IDEs, and Zowe Explorer for coding and integration, Git and Subversion for version control and collaboration, Galasa for testing, and Jenkins and Ant for build automation tools.
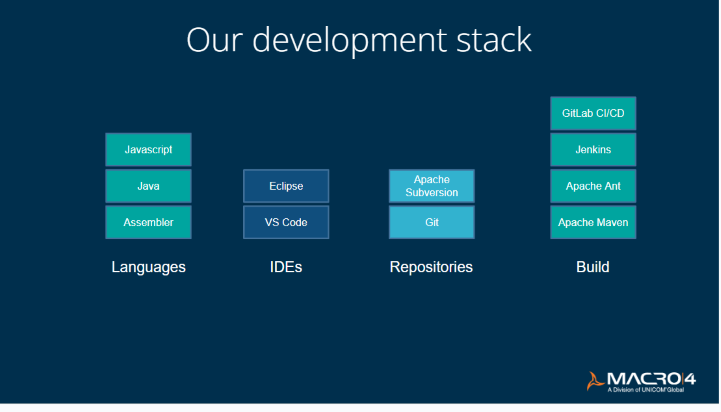
Our development stack today
Macro 4 is an Assembler shop (unusual as many other vendors have moved to other languages such as C). We build system tools for mainframes and for us the granularity of Assembler performs much better than any of the higher-level languages. We also use Java for some back-end development and JavaScript for building interfaces to our products.
We started off using Eclipse as our first open-source IDE, but now we use VS Code, which is newer and becoming much more popular.
Like most mainframe shops we've moved away from using the mainframe natively as a repository. Initially, we used Apache Subversion, but now also use Git, which is probably the market leader. This affords all the expected benefits of better control and versioning for the code or portions of code.
To manage and automate the build, we use a combination of Jenkins, Apache Ant, Apache Maven and GitLab CI/CD.
What were the main drivers for change?
There were many reasons including:
- The increasing demand for dedicated IDEs that provide all sorts of code assistance was preferable to working with the generic green-screen ISPF interface.
- z/OS became less isolated with developers from other areas with different expectations, bringing fresh ideas and new ways of doing things.
- The emergence of what are perceived to be newer modern languages such as Java and Python which are constantly changing.
- Dedicated repositories that had the potential to be used for z/OS and have since become a standard. The tendency before was to manage your code in a file-based repository under z/OS with the ISPF interface (although there were mainframe repositories such as Endevor from CA (now BroadCom).
- The emergence of open-source software which has now become enormously widespread with a large developer community contributing to individual open-source projects.
- Increasing regulatory compliance which demanded more transparency and standardization.
Today, many organizations that run mainframes say they use many of these same open-source tools that I am describing here. They are likely to have been influenced by many of the same drivers. But what was the process that got them there? What did they do to integrate all these open-source products? What are some of the advantages and the problems that need to be tackled along the way? Those are some of the questions I will try to answer from a Macro 4 perspective in the next couple of blog articles.
This blog was originally published on the IBM Community.